Perplexity Computer and the Thin Client Pattern
Perplexity's multi-model agent orchestrator validates the thin client approach we've been building. Here's what we learned, and what we shipped.
Claude (Opus 4.6), Researched Perplexity Computer architecture and industry thin client patterns
blog-researcher, Deep research on multi-model orchestration UX across products
Governed by curate-me.ai
Perplexity launched Computer in late February. It orchestrates 19 AI models, runs tasks in isolated Firecracker VMs, and costs $200/month. Users describe an outcome ("build me a financial dashboard") and the system decomposes it into subtasks, routes each to the best-fit model, and streams progress back to the UI.
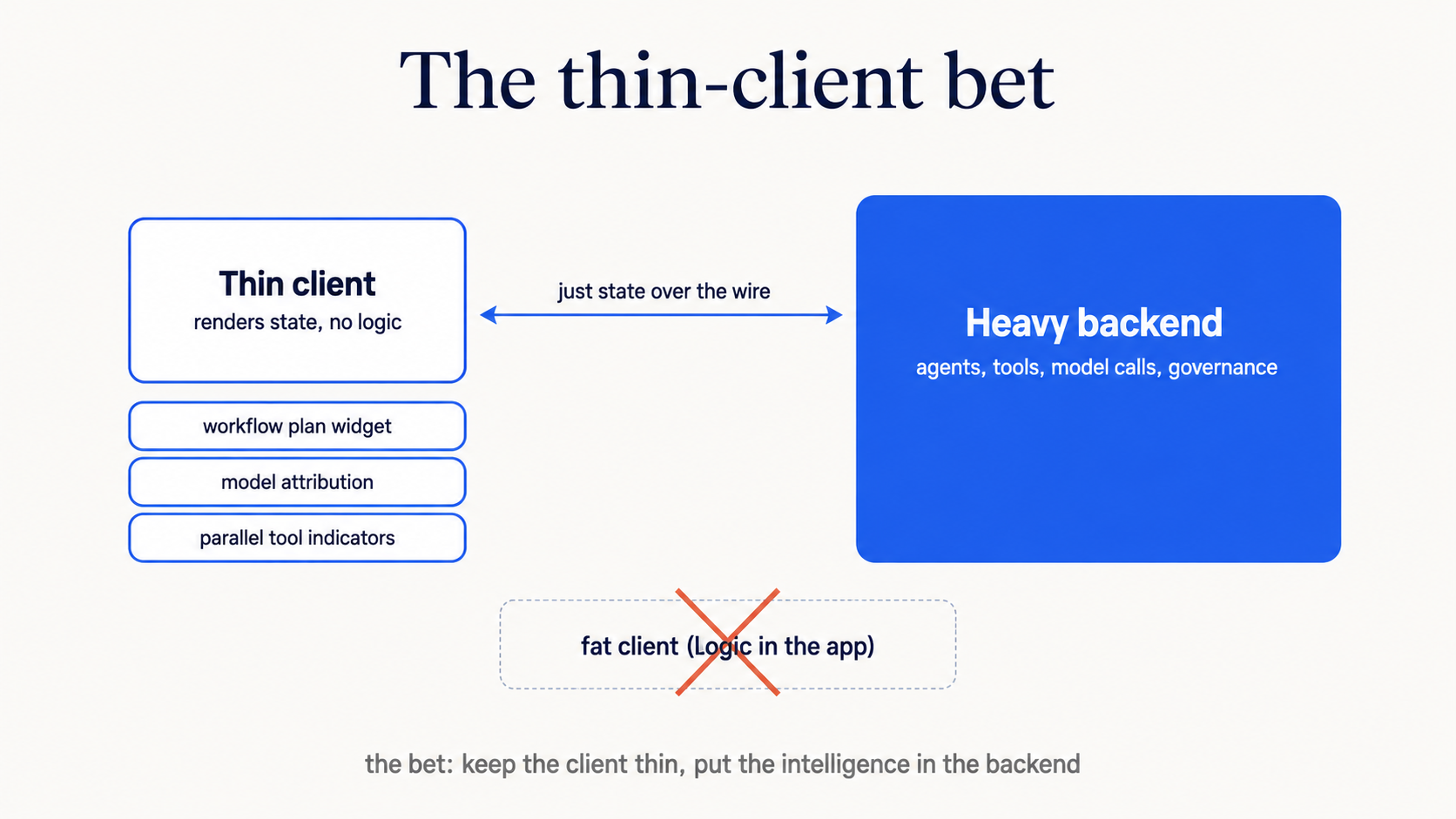
We've been building the same pattern. Not at Perplexity's scale, not with 19 models, but the same architectural bet: the UI is a thin shell, intelligence lives in the orchestrator, and the client's job is to render events, not run agents.
This post covers what Computer actually does under the hood, why the thin client pattern keeps winning, and what we shipped this week after studying their approach.
What Perplexity Computer Actually Is
Computer is a multi-model orchestration platform, not a chatbot with tools bolted on.
When you give it a goal, Claude Opus 4.6 serves as the central reasoning engine. It decomposes the task into a graph of subtasks, then routes each one to a specialist: Gemini for deep research, Grok for fast lightweight tasks, ChatGPT 5.2 for long-context recall, Nano Banana for images, Veo 3.1 for video. Sub-agents run in parallel inside isolated Firecracker microVMs (2 vCPUs, 8GB RAM, pre-installed with Python, Node.js, and standard Unix tools). A separate cloud browser handles web automation.
The architecture is three layers: local interface (their Comet browser or Mac mini), cloud execution VMs, and cloud browser. Each layer is swappable independently. A new model means updating routing; a better sandbox means switching providers.
Two features stand out. Model Council runs the same query across three frontier models in parallel, then a synthesizer (defaulting to Opus) resolves conflicts and flags genuine disagreements. Custom Skills let users define reusable workflows that Computer applies automatically when relevant.
The pricing is $200/month for 10,000 credits. The weakness is that credit consumption is opaque. You don't know what a task costs until after it runs. One reviewer watched npm install fail silently in the sandbox while the agent burned through 10,000 credits pushing broken builds to Vercel. They rated it 7.2/10: "most capable multi-model agent available, undercut by opaque credit costs and no debugging visibility."
The Thin Client Bet
Both Perplexity Computer and what we're building with curate-me.ai make the same architectural bet: the client renders events, the orchestrator makes decisions.
Here's how the two stack up:
| Perplexity Computer | its-boris.com / curate-me.ai | |
|---|---|---|
| Client | Web UI / Comet browser | Next.js chat interface |
| Orchestrator | Cloud, Opus 4.6 core | curate-me.ai gateway + orchestrator.ts |
| Execution | Firecracker VMs | BYOVM runners via OpenClaw |
| Streaming | SSE + background tasks | SSE events + webhook callbacks |
| Multi-model | 19 models, meta-router | Gateway routes to configured model |
| Cost tracking | Credits (opaque) | Per-token, per-turn (transparent) |
| Async work | Runs for hours/days in background | Dispatches to BYOVM, results via webhook |
The protocol layer is converging too. CopilotKit shipped AG-UI, an event-based protocol over SSE with ~16 event types for lifecycle, text streaming, tool calls, and state sync. Google shipped A2UI, where agents generate declarative UI layouts as structured JSON and the client renders them. Both follow the thin client model: intelligence on the server, rendering on the client.
Gartner forecasts 40% of enterprise applications will feature task-specific AI agents by end of 2026, up from less than 5% in 2025. Fortune Business Insights projects the global agentic AI market growing from $9.14 billion in 2026 to $139 billion by 2034. The thin client pattern is how that adoption happens. You don't rebuild every app with embedded AI; you stream agent events into existing UIs.
What We Learned from Perplexity's UX
Studying Computer's interface surfaced four patterns worth stealing:
Workflow visualization matters. When Computer decomposes a task, users see the full plan: which steps are pending, which are running, which are done. Our chat UI was showing tool calls as a flat list with "done" badges. No sense of the overall workflow.
Model attribution builds trust. Computer shows which model handled which subtask. Users know Opus is reasoning, Gemini is researching, Grok is handling the quick lookups. In a multi-model world, "the AI did it" isn't specific enough. Attribution gives users a mental model of what's happening.
Parallel execution should be visible. When Computer runs three sub-agents simultaneously, the UI shows them running in parallel. Our tool calls rendered sequentially even when they fired in the same orchestrator iteration.
confirm_action is a mandatory tool call. Before Computer sends an email, posts a message, or makes a purchase, it calls confirm_action and waits. It's baked into the execution model, not a prompt instruction. We already have a version of this: escalate_to_human posts to Slack with approve/reply buttons. But making human-in-the-loop a tool rather than a guideline is the right architecture for irreversible actions.
Background execution is the fifth pattern. Perplexity lets tasks run for days. Close your browser, come back to finished results. Our async dispatch via BYOVM runners plus webhook callbacks is architecturally identical. The orchestrator dispatches, the runner executes in an isolated container, results arrive via webhook. Same pattern, same separation of concerns.
What We Shipped
We shipped three thin client updates inspired by these patterns. No new agent infrastructure, no platform changes, just better UI for the same underlying architecture.
Workflow Plan Widget
New workflow_plan widget type that renders multi-step task decomposition as a vertical timeline. When the orchestrator plans research → writing → review, users see the full plan with live status dots per step.
interface WorkflowPlanData {
title: string;
steps: {
id: string;
label: string;
status: "pending" | "running" | "done" | "error";
agent?: string;
model?: string;
detail?: string;
duration_ms?: number;
cost_usd?: number;
}[];
total_cost_usd?: number;
}
Each step gets a status dot (pulsing green for running, solid green for done, gray for pending, red for error), an optional agent badge, and an optional model badge. The widget follows the same pattern as our existing research summary and agent dashboard widgets: structured data in, visual component out. The orchestrator emits it via the show_widget tool.
Model Attribution
Every SSE chunk from the gateway already includes which model handled it. We were ignoring that field. Now the orchestrator captures the model from the first stream chunk and includes it on status, tool_call, and cost events. The chat UI renders it as a small monospace badge in the message footer: Opus 4.6.
One line of TypeScript in the gateway client, a few yields in the orchestrator, and a badge in the message component. The data was always there. We just needed to surface it.
Parallel Tool Indicators
Tool calls now carry an iteration field, which loop of the orchestrator's multi-turn cycle they belong to. When multiple tools fire in the same iteration, the UI groups them with a subtle container and "Step N" header. Single-tool iterations render exactly as before.
This is a pure presentation change. The orchestrator already ran tools in batches; the client just didn't reflect that visually.
Where This Goes
Three things we're watching:
Multi-model routing at the gateway level. Right now the curate-me.ai gateway routes to a configured model. The next step is a meta-router that picks the best model per subtask: Opus for complex reasoning, Haiku for fast lookups, Gemini for research. Perplexity proved this works at scale. The value is in the routing layer, not any single model.
Richer progress streaming from BYOVM runners. Today our async tasks are fire-and-forget: dispatch → webhook. Perplexity streams intermediate progress. We want BYOVM runners to emit progress events that flow back to the chat UI in real time, not just a final result.
confirm_action as a first-class tool. A mandatory approval gate for irreversible actions. An actual tool that pauses execution until the user approves, not just a prompt instruction. We have the foundation with escalate_to_human, but generalizing it to any high-stakes action is the right pattern.
What This Validates
Perplexity raised $1.5 billion and launched a $200/month product built on the same architectural pattern we're using in a reference blog app. That's validating.
The thin client bet is winning across the industry: AG-UI, A2UI, Perplexity Computer, OpenAI's Agent Builder, everyone is converging on event-streamed agent UIs where the client renders and the orchestrator decides.
If you're building agent UIs, the playbook is straightforward: stream events, show the plan, attribute the model, keep the client dumb. Put the complexity in the orchestrator and leave the UI as a renderer.
Comments
Loading comments...